Liste des séquences
Présentation des bases de données relationnelles.
Nécessité de stocker les données structurées.
Les systèmes de gestion de bases de données sont particulièrement adaptés pour gérer de grands volumes de données : ils permettent de les stocker de façon organisée, et ils offrent des outils adaptés à la manipulation et à l'interrogation de ces grands volumes. Ils intègrent parfois (comme c'est le cas de Microsoft Access ou WinDev) des outils de développement et de création d'interfaces graphiques, qui permettent de générer de toute pièce des applications basées sur les données stockées dans la base.
Les systèmes de gestion de bases de données se révèlent donc particulièrement efficaces pour les applications basées sur le stockage et le traitement des données, applications qui concernent des domaines aussi divers que la gestion d'une entreprise (gestion des produits depuis leur commande jusqu'à leur vente en passant par le stock, les prévisions, etc., gestion des clients, des salariés et des commerciaux), la gestion d'organisations diverses (adhérents d'une association, manifestations d'un club de sports, élèves d'un établissement scolaire), et la gestion personnelle (gestion de cédéthèques, vidéothèques, gestion des contacts, etc.). Les exemples ne manquent pas et ceci n'en est qu'une infime représentation.
Autres méthodes de stockage des données.
Les bases de données relationnelles représentent le moyen le plus répandu de stocker les données, mais pas le seul. Il existe aussi :
- Les fichiers : vous pouvez stocker vos données dans un simple fichier, sans que ce fichier soit pris en charge par un moteur de base de données. C'est donc vous qui allez écrire le code de programmation permettant de gérer les données dans ce fichier. Exemple : les fichiers de configuration des applications.
- Les bases de données hiérarchiques : les données ne sont pas organisées en tables, mais en structure arborescente où chaque donnée a un seul parent. Exemple : la base de registre de Microsoft Windows.
- Les bases de données réseau : contrairement au modèle hiérarchique, les données ne sont pas reliées à un seul parent mais à n'importe quelle autre donnée.
- Le NoSQL : nouveauté de 2009, désigne des bases de données
non relationnelles, utilisées par de grands acteurs comme Google ou FaceBook.
Précisions sur Wikipedia :
http://fr.wikipedia.org/wiki/Nosql
Les SGBDR les plus répandus.
Des systèmes de gestion de bases de données relationnelles parmi les plus utilisés sont :
- Access de Microsoft, inclus dans certaines versions du Pack Office ;
- SQL Server de Microsoft, qui a une orientation beaucoup plus professionnelle qu'Access ;
- Oracle, également très orienté professionnel ;
- MySQL qui était à l'origine orienté Internet, est en double-licence libre et propriétaire. On le retrouve chez la plupart des hébergeurs de sites Web. Il appartient à Oracle depuis le rachat de SUN par Oracle en 2009.
- SQLite par D. Richard Hipp (société Hwaci) est un moteur très léger, qui n'a pas besoin d'installation mais peut être inclus directement dans les programmes que vous distribuez. C'est donc une solution excellente si vos applications, destinées à être déployées chez d'autres personnes, doivent utiliser un SGBDR. Par exemple, il est utilisé dans le navigateur FireFox et dans le logiciel Skype.
Modèle relationnel
Diapo explicationExemple d'un Modèle conceptuel de données
A ce jour, quelle est la toute dernière version de Microsoft Access ?
A ce jour, quelle est la toute dernière version de MySQL ?
Donnez plus d'explication sur le fait que MySQL ait une double licence ?
Vocabulaire


La clé primaire.
Qu'est-ce qu'une clé primaire ?
La notion de clé primaire (appelée aussi identifiant) est une notion fondamentale dans les bases de données relationnelles, nous allons l'expliquer ici.
La valeur de la clé primaire permet d'identifier de façon unique un enregistrement (par exemple, l'animal n°1'). C'est important car, lorsque nous ferons référence à cet animal à partir d'une autre table (par exemple pour dire qu'une demande d'adoption est associée à cet animal), nous utiliserons cette clé primaire. C'est pourquoi il est important que la clé primaire identifie de façon unique et stable l'animal (en général, l'enregistrement) en question. Les clés primaires doivent avoir les propriétés suivantes :
- Elles sont stables, ce qui signifie que la valeur d'une clé primaire ne doit pas varier dans le temps. Par exemple, un numéro d'immatriculation (avant 2009) ne peut servir de clé primaire pour une voiture car il peut changer dans le temps (en cas de changement de département).
- Elles doivent être uniques, ce qui signifie qu'une valeur de la clé désigne un et un seul enregistrement. Par exemple, le numéro de sécurité sociale ne peut servir d'identifiant car un même numéro peut désigner plusieurs personnes : un parent et ses enfants mineurs. D'autre part, la législation française interdit l'utilisation du numéro de sécurité sociale comme identifiant dans les bases de données (pour protéger les libertés individuelles, et plus précisément pour ne pas faciliter les recoupements de fichiers).
- Elles ne doivent pas être réutilisables. Cela signifie que si une valeur a déjà servi de clé primaire pour un enregistrement qui a été supprimé, alors cette même valeur ne pourra plus jamais servir de clé primaire pour un nouvel enregistrement.
Clés naturelles et clés artificielles.
Pour le choix de la clé primaire, on peut choisir une clé naturelle, c'est à dire une valeur existant dans le problème que l'on informatise. Par exemple, une référence de produit pourrait servir de clé primaire.
Toutefois, l'utilisation de clés naturelles peut s'avérer inappropriée si la clé ne respecte pas les propriétés énoncées ci-dessus. On l'a vu, un numéro d'immatriculation de voiture (avant 2009) ou un numéro de sécurité sociale ne peuvent servir de clé primaire. De plus, les clés naturelles ne sont pas forcément optimales au niveau de l'occupation mémoire et des vitesses de traitement.
Je recommande donc l'utilisation systématique de clés artificielles, c'est-à-dire une clé créée de toute pièce car elle n'existe pas dans le système d'information d'origine. Cela nous assure qu'elle aura toutes les propriétés d'une bonne clé primaire.
Numéro automatique.
Un numéro automatique est un entier long, qui occupe 4 octets en mémoire (soit 32 bits), et permet donc de représenter 232 = 4 milliards d'enregistrements différents, ce qui est suffisant dans la quasi-totalité des problèmes. Lorsqu'on crée un nouvel enregistrement, le SGBDR choisit automatiquement une nouvelle valeur pour la clé primaire, c'est le principe du numéro automatique.
La notion de numéro automatique est présente dans tous les systèmes de gestion de bases de données. C'est un type de données parfaitement approprié pour gérer les clés artificielles.
Clé étrangères et intégrité référentielle.
La clé étrangère.
La clé étrangère n'est pas forcément la clé primaire d'une table. Par contre, elle est reliée à une clé primaire dans une autre table.
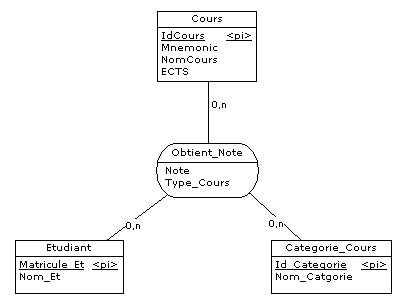
Par exemple, dans le schéma ci-dessous :
- id est la clé primaire de la table Animal.
- IdEspece est une clé étrangère qui fait référence au champ IdEspece de la table espece.
La contrainte d'intégrité référentielle.
L'intégrité référentielle est une notion importante dans les bases de données relationnelles. Cela consiste à vérifier, quand on donne une valeur à un champ dans une clé étrangère, que cette valeur existe dans la table liée. Par exemple, si je crée un animal, il faut que le numéro de l'espèce existe dans la table especes.
On dit que l'intégrité de la base n'est plus respectée lorsque on tombe sur des cas où des clés étrangères existent, mais pas la clé primaire correspondante. Selon le SGBDR et la façon dont il est utilisé, il vous avertira par une erreur ou il laissera faire.
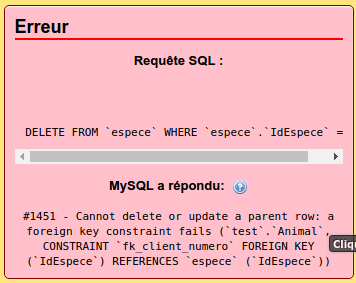
Par exemple, voici l'erreur obtenue sous MYSQL quand je crée animal avec un numéro d'espèce qui n'existe pas :
Remarque sur... L'intégrité référentielle dans MySQL.
- MyISAM est le moteur de stockage par défaut dans MySQL, et il ne gère pas les contraintes d'intégrité référentielle, ce qui implique qu'il ne vous avertira pas lorsque l'intégrité de la base n'est plus respectée. En contrepartie, il est plus performant.
- InnoDB est un des moteurs de stockage les plus utilisés dans MySQL, et il gère les contraintes d'intégrité. En contrepartie, il est moins performant (notamment au niveau de l'espace mémoire occupé par les données).
Pour choisir le moteur de stockage lorsqu'on crée une table dans MySQL :
CREATE TABLE table1 (...) ENGINE = INNODB ;
CREATE TABLE table1 (...) ENGINE = MYISAM ;
Pour changer le moteur de stockage d'une table existante :
ALTER TABLE table1 ENGINE = INNODB ;
ALTER TABLE table1 ENGINE = MYISAM ;
Attention:
travailler avec les contraintes d'intégrité n'est pas une obligation. c'est un choix avec des avantages et des inconvénients.Interroger les bases de données relationnelles.
En tant que futurs professionnels de l'informatique, cette méthode ne nous intéresse pas car elle a ses limites, et on ne peut pas l'intégrer à nos propres applications.
Le langage SQL : Structured Query Language.
Le langage SQL permet d'aller beaucoup plus loin en matière d'interrogation des données. Il permet également de créer les tables, insérer les données, gérer les utilisateurs et leurs droits, etc.
Par exemple, en SQL :
SELECT IdEspece,sexe,date_de_naissance,nom
FROM Animal
WHERE IdEspece = 0
ORDER BY IdEspece ;
Intégration des requêtes dans une application.
Sur l'exemple du site pcm2013.free.fr, montrez des requêtes SQL.
Quelle est l'année de création du langage SQL ?
A quelle version en sommes-nous maintenant ?
Les réponses sont désactivées pour les visiteurs anonymes.
Nécessité de protéger les données.
Les entreprises stockent toutes leurs données dans des bases de données. En cas de problème (crash, piratage), c'est toute la mémoire de l'entreprise qui peut disparaître. Pour éviter cela, il faut :
- sauvegarder régulièrement les données de la base de données ;
- répliquer les données : pour simplifier, un autre SGBDR, sur une autre machine, gère les mêmes données ;
- limiter les accès physiques aux machines qui hébergent les données ;
- limiter les accès logiques aux SGBDR, grâce à une gestion appropriée des comptes d'utilisateurs et des droits associés ;
- etc.
Des cours ultérieurs permettront de voir comment gérer cette sécurité.
Vous aussi vous risquez d'être confrontés à la perte de données. Ca peut être lourd de conséquences si vous perdez des documents de travail qui vous serviront pour valider le BTS. Avez-vous l'intention de faire des sauvegardes régulières de vos travaux (par exemple sur clé USB), ou pas ?